Wolmer’s Trust High School for Girls
CAPE COMPUTER SCIENCE
Grade : Upper and Lower Six Teacher: Mrs. McCallum-Rodney
ABSTRACT DATA TYPES (ADTs)
Introduction
Unfortunately, no matter how many and what data types a language supports directly, for most applications the in-built data types are not sufficient. In many cases, the programmer wants to manipulate entities that are relevant to his or her application but which do not directly correspond to any of the in-built data types. Thus, a programmer who is writing a banking system is not primarily interested in integers, characters or arrays of characters and strings. He or she is far more interested in accounts and their balances, account holders and their names and addresses and so forth. Similarly, a programmer who is writing a student registration system is likely to be interested in students and courses.
It will be clear that the identification of the entities that are relevant to a particular application, the information that needs to be stored and the operations that can be performed on them is of the utmost importance in the design and implementation of almost all computer programs, and an important task in the design of any computer program therefore is the identification and specification of the entities that the program is to manipulate. These specifications of data that the program is to manipulate are often referred to as Abstract Data Types or ADTs.
Definition of an Abstract Data Type
An Abstract Data Type is a mathematically specified entity with a number of attributes and a number of operations defined on it.
Þ It is a set of data values and associated operations that are precisely specified independent of any particular implementation.
Þ ADTs are used to define a new type from which instances can be created.
The Two Parts of an ADT
Each ADT description consists of two parts:
o Data
§ This part describes the structure of the data used in the ADT in an informal way.
o Operations:
§ This part describes valid operations for this ADT, hence, it describes its interface. We use the special operation constructor to describe the actions which are to be performed once an entity of this ADT is created and destructor to describe the actions which are to be performed once an entity is destroyed. For each operation the provided arguments as well as preconditions and postconditions are given.
Three Types of Operations on ADT
1. Constructor Operations
These operations are used to either construct instances of ADT or to set the values of the attributes of the ADT.
2. Accessor Operations
These operations are used to determine the value of any attribute.
3. Testing operations
These operations are used to test whether certain properties are true of an instance of an ADT.
Handling Problems
The first thing with which one is confronted when writing programs is the problem. Typically you are confronted with ``real-life'' problems and you want to make life easier by providing a program for the problem. However, real-life problems are nebulous (vague) and the first thing you have to do is to try to understand the problem to separate necessary from unnecessary details: You try to obtain your own abstract view, or model, of the problem. This process of modeling is called abstraction and is illustrated below.
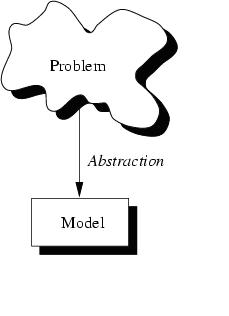 Figure: Create a model from a problem with abstraction.
Figure: Create a model from a problem with abstraction.
The model defines an abstract view to the problem. This implies that the model focuses only on problem related stuff and that you try to define properties of the problem. These properties include
- the data which are affected and
- the operations which are identified
by the problem.
As an example consider the administration of employees in an institution. The head of the administration comes to you and ask you to create a program which allows administering the employees. Well, this is not very specific. For example, what employee information is needed by the administration? What tasks should be allowed? Employees are real persons who can be characterized with many properties; very few are:
- name,
- size,
- date of birth,
- shape,
- social number,
- room number,
- hair colour,
- hobbies.
Certainly not all of these properties are necessary to solve the administration problem. Only some of them are problem specific. Consequently you create a model of an employee for the problem. This model only implies properties which are needed to fulfill the requirements of the administration, for instance name, date of birth and social number. These properties are called the data of the (employee) model. Now you have described real persons with help of an abstract employee.
Of course, the pure description is not enough. There must be some operations defined with which the administration is able to handle the abstract employees. For example, there must be an operation which allows you to create a new employee once a new person enters the institution. Consequently, you have to identify the operations which should be able to be performed on an abstract employee. You also decide to allow access to the employees' data only with associated operations. This allows you to ensure that data elements are always in a proper state. For example you are able to check if a provided date is valid.
To sum up, abstraction is the structuring of a nebulous problem into well-defined entities by defining their data and operations. Consequently, these entities combine data and operations. They are not decoupled from each other.
Properties of Abstract Data Types
The previous example shows that with abstraction you create a well-defined entity which can be properly handled. These entities define the data structure of a set of items. For example, each administered employee has a name, date of birth and social number.
The data structure can only be accessed with defined operations. This set of operations is called interface and is exported by the entity. An entity with the properties just described is called an abstract data type (ADT).
The figure below shows an ADT which consists of an abstract data structure and operations. Only the operations are viewable from the outside and define the interface.
|
Figure : An abstract data type (ADT). |
|
|
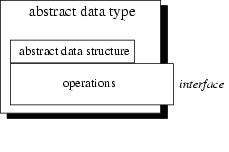
The behavior of an ADT is defined by a set of operations that can be applied to an instance of the ADT.
Each operation of an ADT can have inputs (i.e., parameters) and outputs (i.e., results). The collection of information about the names of the operations and their inputs and outputs is the interface of the ADT.
Specifying and Implementing ADTs
o Merely implementing the ADT is not sufficient. The ADT was specified and implemented because some computer program needed it. The rest of the program will therefore use the ADT.
o It is important that, whenever the programmer uses an ADT, he or she exclusively use the operations defined over the ADT. The exclusive use of the operations defined on the ADT is called “information hiding” or “Data Encapsulation”.
o Different programming languages enforce data encapsulation to a greater or lesser extent. To enforce data encapsulation in C, the discipline of the programmer is important. In a language that does not enforce data encapsulation, a programmer who is aware of the internal representation of an ADT can directly set and access the attributes of an instance of the ADT, bypassing the constructor and accessor operations defined on the ADT.
Advantages of ADTs
v It leads to more modular codes
An ADT, once identified and specified, almost automatically yields a set of independent modules. Modular code has number of different programmers working simultaneously on the same program. Once an ADT has been fully specified, one set of programmers can be given the task of implementing the ADT, while another group of programmers can be given the task of writing the code that uses these ADTs. Moreover, modular code, especially if the modules are given mnemonic names, is typically easier to understand and hence easier to debug and maintain.
v It allows the possibility of re-use of code
It turns out that many programs use very similar ADTs. For example, as we shall see, many programs manipulate information about collections of entities. Thus, a student information system will manipulate information on collections of students and courses. A banking system will manipulate information about collections of bank accounts and bank account holders. It turns out Computer Science has seen the emergence of many different ADTs for handling collections of entities. Clearly, there are many advantages to re-using such ADTs. For example, it is likely that re-using ADTs that have been extensively studied before will allow one to develop programs faster and lead to code with fewer bugs.
Activity 1
Look around you. Can you see any collections in your home or in the school environment? Identify some and write down their properties. Discuss your thoughts with a classmate before the next class.
Think about this example: We need to store information about the group of products in a store. What kind of information do you think would be needed about that group of products? What does the group need to be able to do/have done to it?